Publications
Below you will find a somewhat updated list of publications I have been involved in, you can find most of these from my Google Scholar Page.
Publications
2025
DeepSynBa: A deep learning method to improve drug combination predictions using full dose-response matrices and contextual features of cell lines and cancer indications
Marta Milo, Haoting Zhang, Halil ibrahim Kuru, A Ercument Cicek, Oznur Tastan, Carl Henrik Ek, Magnus Rattray
Cancer Research, 2025
Abstract
Many cancer monotherapies have limited activity in clinic, making combinations a relevant treatment strategy. The number of possible combinations is vast, and the responses can be context-specific, making it challenging to predict combination effects. Existing computational models typically predict a single aggregated synergy score, i.e. Bliss or Loewe, for a given drug combination. However, these approaches exhibit high prediction uncertainty and limited actionability because they fail to differentiate between potency and efficacy by oversimplifying the drug-response surface using a single synergy score.
To address these limitations, we introduce DeepSynBa, which models the full dose-response matrix of drug pairs rather than an aggregated synergy score. DeepSynBa formulates this task as a regression problem and uses cell line-specific features and drug embeddings to predict the entire drug-response matrix within a deep learning framework. Following SynBa’s approach of modelling the dose-response surface [1], DeepSynBa includes an intermediate layer that estimates pharmacological parameters, which are then used to predict dose-response values across dosages. This design also enables post-hoc calculation of traditional synergy scores like Loewe and Bliss, maintaining compatibility with existing synergy predictors.
Linear combinations of Gaussian latents in generative models: interpolation and beyond
Erik Bodin, Alexandru I. Stere, Dragos D Margineantu, Carl Henrik Ek, Henry Moss
ICLR, 2025
Abstract
Sampling from generative models has become a crucial tool for applications like data synthesis and augmentation. Diffusion, Flow Matching and Continuous Normalizing Flows have shown effectiveness across various modalities, and rely on Gaussian latent variables for generation. For search-based or creative applications that require additional control over the generation process, it has become common to manipulate the latent variable directly. However, existing approaches for performing such manipulations (e.g. interpolation or forming low-dimensional representations) only work well in special cases or are network or data-modality specific. We propose Combination of Gaussian variables (COG) as a general purpose method to form linear combinations of latent variables while adhering to the assumptions of the generative model. COG is easy to implement yet outperforms recent sophisticated methods for interpolation. As COG naturally addresses the broader task of forming linear combinations, new capabilities are afforded, including the construction of subspaces of the latent space, dramatically simplifying the creation of expressive low-dimensional spaces of high-dimensional objects.
Efficient Model-Based Reinforcement Learning Through Optimistic Thompson Sampling
Jasmine Bayrooti, Carl Henrik Ek, Amanda Prorok
ICLR, 2025
Abstract
Learning complex robot behavior through interactions with the environment necessitates principled exploration. Effective strategies should prioritize exploring regions of the state-action space that maximize rewards, with optimistic exploration emerging as a promising direction aligned with this idea and enabling sample-efficient reinforcement learning. However, existing methods overlook a crucial aspect: the need for optimism to be informed by a belief connecting the reward and state. To address this, we propose a practical, theoretically grounded approach to optimistic exploration based on Thompson sampling. Our model structure is the first that allows for reasoning about joint uncertainty over transitions and rewards. We apply our method on a set of MuJoCo and VMAS continuous control tasks. Our experiments demonstrate that optimistic exploration significantly accelerates learning in environments with sparse rewards, action penalties, and difficult-to-explore regions. Furthermore, we provide insights into when optimism is beneficial and emphasize the critical role of model uncertainty in guiding exploration.
2024
Reparameterization invariance in approximate Bayesian inference
Hrittik Roy, Marco Miani, Carl Henrik Ek, Philipp Hennig, Marvin Pförtner, Lukas Tatze, Søren Hauberg
NeurIPS, 2024
Abstract
Current approximate posteriors in Bayesian neural networks (BNNs) exhibit a crucial limitation: they fail to maintain invariance under reparameterization, i.e. BNNs assign different posterior densities to different parametrizations of identical functions. This creates a fundamental flaw in the application of Bayesian principles as it breaks the correspondence between uncertainty over the parameters with uncertainty over the parametrized function. In this paper, we investigate this issue in the context of the increasingly popular linearized Laplace approximation. Specifically, it has been observed that linearized predictives alleviate the common underfitting problems of the Laplace approximation. We develop a new geometric view of reparametrizations from which we explain the success of linearization. Moreover, we demonstrate that these reparameterization invariance properties can be extended to the original neural network predictive using a Riemannian diffusion process giving a straightforward algorithm for approximate posterior sampling, which empirically improves posterior fit.
Automatic Knowledge Extraction for Decision Support in the Structural Design Process
Sonja Schlenz, Simon Mößner, Carl Henrik Ek, Fabian Duddeck
, 2024
Abstract
Much of an engineer’s implicit knowledge and experience is embedded in data from previous engineering processes. In the typical automotive structural design process, many simulation variants are created to incrementally improve relevant perfor- mance values. Engineers decide about the modifications to make to the geometry to achieve these improvements. The steps of this development process reflect the engineer’s decisions and thus her/his knowledge and experience. This implicit knowledge is potentially helpful for new projects, but is not easily accessi- ble. This paper proposes a method to automatically extract past solutions from a database containing finite element simulation data from previous development processes. A reference model with high similarity to the problem at hand is identified in the database. Since the development process of this model is already completed, there must exist a later version of the model where the problem has been solved. The difference between the ref- erence model and the identified improved model represents an engineer’s knowledge that was used to solve a similar problem in the past. Possible solutions identified this way are success- fully used to support engineers in their decisions in new projects during the structural design process. The method is applied to pedestrian safety data from the structural design process of cars using real-world data.
Representing engineering design changes in finite element models using directed point cloud autoencoders
Sonja Schlenz, Simon Mößner, Carl Henrik Ek, Fabian Duddeck
, 2024
Abstract
In recent years, the importance of digitalization techniques in the field of engineering has grown rapidly and led to many new applications, allowing analyzing, predicting, and reusing data. An essential type of engineering data is related to finite element models frequently used for simulation, where many small geometric changes occur during a product’s development process. These modifications reflect the engineer’s implicit knowledge, as they show the engineer’s decisions during the development process. While numerous approaches exist to formalize geometric information as a whole, representing only the changes between finite element models, and thus engineers’ knowledge, has not been investigated yet. In this work, a representation of geometric engineering changes between finite element models is presented, which is automatically learned from past engineering data. The representation is based on vectors between variants, whose dimensionality is reduced with a novel directed point cloud autoencoder. It is shown that this representation of change preserves similarities and differences between different geometric changes while being suitable as input for further machine learning applications, enabling further use of the acquired knowledge. To summarize, the objective is to learn from changes and their motivations in finished engineering developments and to transfer the insights to future design processes, i.e., to inspire engineers and make processes more efficient and goal-oriented.
2023
SynBa: Improved estimation of drug combination synergies with uncertainty quantification
Haoting Zhang, Carl Henrik Ek, Magnus Rattray and Marta Milo
Intelligent Systems for Molecular Biology, 2023
Abstract
There exists a range of different quantification frameworks to estimate the synergistic effect of drug combinations. The diversity and disagreement in estimates make it challenging to determine which combinations from a large drug screening should be proceeded with. Furthermore, the lack of accurate uncertainty quantification for those estimates precludes the choice of optimal drug combinations based on the most favourable synergistic effect. In this work, we propose SynBa, a flexible Bayesian approach to estimate the uncertainty of the synergistic efficacy and potency of drug combinations, so that actionable decisions can be derived from the model outputs. The actionability is enabled by incorporating the Hill equation into SynBa, so that the parameters representing the potency and the efficacy can be preserved. Existing knowledge may be conveniently inserted due to the flexibility of the prior, as shown by the empirical Beta prior defined for the normalised maximal inhibition. Through experiments on large combination screenings and comparison against benchmark methods, we show that SynBa provides improved accuracy of dose-response predictions and better-calibrated uncertainty estimation for the parameters and the predictions.
Surface Approximation by Means of Gaussian Process Latent Variable Models and Line Element Geometry
Ivan De Boi, Carl Henrik Ek and Rudi Penne
Mathematics, 2023
Abstract
The close relation between spatial kinematics and line geometry has been proven to be fruitful in surface detection and reconstruction. However, methods based on this approach are limited to simple geometric shapes that can be formulated as a linear subspace of line or line element space. The core of this approach is a principal component formulation to find a best-fit approximant to a possibly noisy or impartial surface given as an unordered set of points or point cloud. We expand on this by introducing the Gaussian process latent variable model, a probabilistic non-linear non-parametric dimensionality reduction approach following the Bayesian paradigm. This allows us to find structure in a lower dimensional latent space for the surfaces of interest. We show how this can be applied in surface approximation and unsupervised segmentation to the surfaces mentioned above and demonstrate its benefits on surfaces that deviate from these. Experiments are conducted on synthetic and real-world objects.
Mode Constrained Model-Based Reinforcement Learning via Gaussian Processes
Aidan Scannell, Carl Henrik Ek and Arthur Richards
AISTATS, 2023
Abstract
Model-based reinforcement learning (RL) algorithms do not typically consider environments with multiple dynamic modes, where it is beneficial to avoid inoperable or undesirable modes. We present a model-based RL algorithm that constrains training to a single dynamic mode with high probability. This is a difficult problem because the mode constraint is a hidden variable associated with the environment’s dynamics. As such, it is 1) unknown a priori and 2) we do not observe its output from the environment, so cannot learn it with supervised learning. We present a nonparametric dynamic model which learns the mode constraint alongside the dynamic modes. Importantly, it learns latent structure that our planning scheme leverages to 1) enforce the mode constraint with high probability, and 2) escape local optima induced by the mode constraint. We validate our method by showing that it can solve a simulated quadcopter navigation task whilst providing a level of constraint satisfaction both during and after training.
2022
Identifying Latent Distances with Finslerian Gemoetry
Alison Pouplin, Carl Henrik Ek, David Eklund, Søren Hauberg sohau@dtu.dk
NeurIPS Workshop, 2022
Abstract
Riemannian geometry has been shown useful to explore the latent space of generative models. Effectively, we can endow the latent space with the pullback metric obtained from the data space. Because most generative models are stochastic, this metric will be de facto stochastic, and, as a consequence, a deterministic approximation of the metric is required. Here, we are defining a new metric as the expectation of the stochastic curve lengths induced by the pullback metric. We show this metric is, in fact, a Finsler metric. We compare it with a previously studied expected Riemannian metric, and we show that in high dimensions, the metrics converge to each other.
Aligned Multi-Task Gaussian Process
O. Mikheeva, I. Kazlauskaite, A. Hartshorne, H. Kjellström, C. H. Ek, N. D. F. Campbell
AISTATS, 2022
Abstract
Multi-task learning requires accurate identification of the correlations between tasks. In real-world time-series, tasks are rarely perfectly temporally aligned; traditional multi-task models do not account for this and subsequent errors in correlation estimation will result in poor predictive performance and uncertainty quantification. We introduce a method that automatically accounts for temporal misalignment in a unified generative model that improves predictive performance. Our method uses Gaussian processes (GPs) to model the correlations both within and between the tasks. Building on the previous work by Kazlauskaiteet al. [2019], we include a separate monotonic warp of the input data to model temporal misalignment. In contrast to previous work, we formulate a lower bound that accounts for uncertainty in both the estimates of the warping process and the underlying functions. Also, our new take on a monotonic stochastic process, with efficient path-wise sampling for the warp functions, allows us to perform full Bayesian inference in the model rather than MAP estimates. Missing data experiments, on synthetic and real time-series, demonstrate the advantages of accounting for misalignments (vs standard unaligned method) as well as modelling the uncertainty in the warping process(vs baseline MAP alignment approach).
2021
Deep Neural Networks as Point Estimates for Deep Gaussian Processes
V. Dutordoir, J. Hensman, M. van der Wilk, C. H. Ek, Z. Ghahramani, N. Durrande
NeurIPS, 2021
Abstract
Deep Gaussian processes (DGPs) have struggled for relevance in applications due to the challenges and cost associated with Bayesian inference. In this paper we propose a sparse variational approximation for DGPs for which the approximate posterior mean has the same mathematical structure as a Deep Neural Network (DNN). We make the forward pass through a DGP equivalent to a ReLU DNN by finding an interdomain transformation that represents the GP posterior mean as a sum of ReLU basis functions. This unification enables the initialisation and training of the DGP as a neural network, leveraging the well established practice in the deep learning community, and so greatly aiding the inference task. The experiments demonstrate improved accuracy and faster training compared to current DGP methods, while retaining favourable predictive uncertainties.
Black-box density function estimation using recursive partitioning
E. Bodin, Z. Dai, N. D. F. Campbell, C. H. Ek
ICML, 2021
Abstract
We present a novel approach to Bayesian inference and general Bayesian computation that is defined through a sequential decision loop. Our method defines a recursive partitioning of the sample space. It neither relies on gradients nor requires any problem-specific tuning, and is asymptotically exact for any density function with a bounded domain. The output is an approximation to the whole density function including the normalisation constant, via partitions organised in efficient data structures. Such approximations may be used for evidence estimation or fast posterior sampling, but also as building blocks to treat a larger class of estimation problems. The algorithm shows competitive performance to recent state-of-the-art methods on synthetic and real-world problems including parameter inference for gravitational-wave physics.
Multi-view Learning as a Nonparametric Nonlinear Inter-Battery Factor Analysis
A. Damianou, N. D. Lawrence, C. H. Ek
JMLR, 2021
Abstract
Factor analysis aims to determine latent factors, or traits, which summarize a given data set. Inter-battery factor analysis extends this notion to multiple views of the data. In this paper we show how a nonlinear, nonparametric version of these models can be recovered through the Gaussian process latent variable model. This gives us a flexible formalism for multi-view learning where the latent variables can be used both for exploratory purposes and for learning representations that enable efficient inference for ambiguous estimation tasks. Learning is performed in a Bayesian manner through the formulation of a variational compression scheme which gives a rigorous lower bound on the log likelihood. Our Bayesian framework provides strong regularization during training, allowing the structure of the latent space to be determined efficiently and automatically. We demonstrate this by producing the first (to our knowledge) published results of learning from dozens of views, even when data is scarce. We further show experimental results on several different types of multi-view data sets and for different kinds of tasks, including exploratory data analysis, generation, ambiguity modelling through latent priors and classification.
Trajectory Optimisation in Learned Multimodal Dynamical Systems Via Latent-ODE Collocation
A. Scannell, C. H. Ek, A. Richards
IROS, 2021
Abstract
This paper presents a two-stage method to perform trajectory optimisation in multimodal dynamical systems with unknown nonlinear stochastic transition dynamics. The method finds trajectories that remain in a preferred dynamics mode where possible and in regions of the transition dynamics model that have been observed and can be predicted confidently. The first stage leverages a Mixture of Gaussian Process Experts method to learn a predictive dynamics model from historical data. Importantly, this model learns a gating function that indicates the probability of being in a particular dynamics mode at a given state location. This gating function acts as a coordinate map for a latent Riemannian manifold on which shortest trajectories are solutions to our trajectory optimisation problem. Based on this intuition, the second stage formulates a geometric cost function, which it then implicitly minimises by projecting the trajectory optimisation onto the second-order geodesic ODE; a classic result of Riemannian geometry. A set of collocation constraints are derived that ensure trajectories are solutions to this ODE, implicitly solving the trajectory optimisation problem.
2020
Modulating Surrogates for Bayesian Optimization
E. Bodin, M. Kaiser, I. Kazlauskaite, Z. Dai, N. D. F. Campbell, C. H. Ek
ICML, 2020
Abstract
Bayesian optimization (BO) methods often rely on the assumption that the objective function is well-behaved, but in practice, this is seldom true for real-world objectives even if noise-free observations can be collected. Common approaches, which try to model the objective as precisely as possible, often fail to make progress by spending too many evaluations modeling irrelevant details. We address this issue by proposing surrogate models that focus on the well-behaved structure in the objective function, which is informative for search, while ignoring detrimental structure that is challenging to model from few observations. First, we demonstrate that surrogate models with appropriate noise distributions can absorb challenging structures in the objective function by treating them as irreducible uncertainty. Secondly, we show that a latent Gaussian process is an excellent surrogate for this purpose, comparing with Gaussian processes with standard noise distributions. We perform numerous experiments on a range of BO benchmarks and find that our approach improves reliability and performance when faced with challenging objective functions.
Compositional uncertainty in deep Gaussian processes
I. Ustyuzhaninov, I. Kazlauskaite, M. Kaiser, E. Bodin, N. D. F. Campbell, C. H. Ek
UAI, 2020
Abstract
Gaussian processes (GPs) are nonparametric priors over functions, and fitting a GP to the data implies computing the posterior distribution of the functions consistent with the observed data. Similarly, deep Gaussian processes (DGPs) [Damianou:2013] should allow us to compute the posterior distribution of compositions of multiple functions giving rise to the observations. However, exact Bayesian inference is usually intractable for DGPs, motivating the use of various approximations. We show that the simplifying assumptions for a common type of Variational inference approximation imply that all but one layer of a DGP collapse to a deterministic transformation. We argue that such an inference scheme is suboptimal, not taking advantage of the potential of the model to discover the compositional structure in the data, and propose possible modifications addressing this issue.
Bayesian decomposition of multi-modal dynamical systems for reinforcement learning
M. Kaiser, C. Otte, T. Runkler, C. H. Ek
Neurocomputing, 2020
Abstract
In this paper, we present a model-based reinforcement learning system where the transition model is treated in a Bayesian manner. The approach naturally lends itself to exploit expert knowledge by introducing priors to impose structure on the underlying learning task. The additional information introduced to the system means that we can learn from small amounts of data, recover an interpretable model and, importantly, provide predictions with an associated uncertainty. To show the benefits of the approach, we use a challenging data set where the dynamics of the underlying system exhibit both operational phase shifts and heteroscedastic noise. Comparing our model to NFQ and BNN+LV, we show how our approach yields human-interpretable insight about the underlying dynamics while also increasing data-efficiency.
Visual and tactile 3D point cloud data from real robots for shape modeling and completion
Y. Bekiroglu, M. Björkman, G. Zarzar Gandler, J. Exner, C. H. Ek, D. Kragic
Data in Brief, 2020
Abstract
Representing 3D geometry for different tasks, e.g. rendering and reconstruction, is an important goal in different fields ranging from computer graphics, computer vision and robotics. Robotic applications often require perception of object shape information, extracted from sensory data that can be noisy and incomplete. This is a challenging task and in order to facilitate analysis of new methods and comparison of different approaches for shape modeling (e.g. surface estimation), completion and exploration, we provide real sensory data acquired from exploring various objects of different complexities. The dataset includes visual and tactile readings in the form of 3D point clouds obtained using two different robot setups that are equipped with visual and tactile sensors. During data collection, the robots touch the experiment objects in a predefined manner at various exploration configurations and gather visual and tactile points in the same coordinate frame based on calibration between the robots and the used cameras. The goal of this exhaustive exploration procedure is to sense unseen parts of objects which are not visible to the fixed camera, but can be sensed via tactile sensors activated at touched areas. The data was used for shape completion and modeling via Implicit Surface representation and Gaussian-Process-based regression, in the work “Object shape estimation and modeling, based on sparse Gaussian process implicit surfaces, combining visual data and tactile exploration” [3], and also used partially in “Enhancing visual perception of shape through tactile glances” [4], both studying efficient exploration of objects to reduce number of touches.
Monotonic Gaussian Process Flow
I. Ustyuzhaninov, I. Kazlauskaite, C. H. Ek, N. D. F. Campbell
AISTATS, 2020
Abstract
We propose a new framework of imposing monotonicity constraints in a Bayesian non-parametric setting. Our approach is based on numerical solutions of stochastic differential equations [Hedge, 2019]. We derive a non-parametric model of monotonic functions that allows for interpretable priors and principled quantification of hierarchical uncertainty. We demonstrate the efficacy of the proposed model by providing competitive results to other probabilistic models of monotonic functions on a number of benchmark functions. In addition, we consider the utility of a monotonic constraint in hierarchical probabilistic models, such as deep Gaussian processes. These typically suffer difficulties in modelling and propagating uncertainties throughout the hierarchy that can lead to hidden layers collapsing to point estimates. We address this by constraining hidden layers to be monotonic and present novel procedures for learning and inference that maintain uncertainty. We illustrate the capacity and versatility of the proposed framework on the task of temporal alignment of time-series data where it is beneficial to preserve the uncertainty in the temporal warpings.
Object shape estimation and modeling, based on sparse Gaussian process implicit surfaces, combining visual data and tactile exploration
G. Zarzar Gandler, C. H. Ek, M. Björkman, R. Stolkin, Y. Bekiroglu
Robotics and Autonomous Systems, 2020
Abstract
Inferring and representing three-dimensional shapes is an important part of robotic perception. However, it is challenging to build accurate models of novel objects based on real sensory data, because observed data is typically incomplete and noisy. Furthermore, imperfect sensory data suggests that uncertainty about shapes should be explicitly modeled during shape estimation. Such uncertainty models can usefully enable exploratory action planning for maximum information gain and efficient use of data. This paper presents a probabilistic approach for acquiring object models, based on visual and tactile data. We study Gaussian Process Implicit Surface (GPIS) representation. GPIS enables a non-parametric probabilistic reconstruction of object surfaces from 3D data points, while also providing a principled approach to encode the uncertainty associated with each region of the reconstruction. We investigate different configurations for GPIS, and interpret an object surface as the level-set of an underlying sparse GP. Experiments are performed on both synthetic data, and also real data sets obtained from two different robots physically interacting with objects. We evaluate performance by assessing how close the reconstructed surfaces are to ground-truth object models. We also evaluate how well objects from different categories are clustered, based on the reconstructed surface shapes. Results show that sparse GPs enable a reliable approximation to the full GP solution, and the proposed method yields adequate surface representations to distinguish objects. Additionally the presented approach is shown to provide computational efficiency, and also efficient use of the robot’s exploratory actions.
2019
Compositional uncertainty in deep Gaussian processes
I. Ustyuzhaninov, I. Kazlauskaite, M. Kaiser, E. Bodin, N. D. F. Campbell, C. H. Ek
NeurIPS Workshops, 2019
Abstract
Gaussian processes (GPs) are nonparametric priors over functions, and fitting a GP to the data implies computing the posterior distribution of the functions consistent with the observed data. Similarly, deep Gaussian processes (DGPs) [Damianou:2013] should allow us to compute the posterior distribution of compositions of multiple functions giving rise to the observations. However, exact Bayesian inference is usually intractable for DGPs, motivating the use of various approximations. We show that the simplifying assumptions for a common type of Variational inference approximation imply that all but one layer of a DGP collapse to a deterministic transformation. We argue that such an inference scheme is suboptimal, not taking advantage of the potential of the model to discover the compositional structure in the data, and propose possible modifications addressing this issue.
Data Association with Gaussian Processes
M. Kaiser, C. Otte, T. Runkler, C. H. Ek
European Conference on Machine Learning (ECML), 2019
Abstract
The data association problem is concerned with separating data coming from different generating processes, for example when data comes from different data sources, contain significant noise, or exhibit multimodality. We present a fully Bayesian approach to this problem. Our model is capable of simultaneously solving the data association problem and the induced supervised learning problem. Underpinning our approach is the use of Gaussian process priors to encode the structure of both the data and the data associations. We present an efficient learning scheme based on doubly stochastic variational inference and discuss how it can be applied to deep Gaussian process priors.
DP-GP-LVM: A Bayesian Non-Parametric Model for Learning Multivariate Dependency Structures
A. Lawrence, C. H. Ek, N. D. F. Campbell
International Conference on Machine Learning (ICML), 2019
Abstract
We present a non-parametric Bayesian latent variable model capable of learning dependency structures across dimensions in a multivariate setting. Our approach is based on flexible Gaussian process priors for the generative mappings and interchangeable Dirichlet process priors to learn the structure. The introduction of the Dirichlet process as a specific structural prior allows our model to circumvent issues associated with previous Gaussian process latent variable models. Inference is performed by deriving an efficient variational bound on the marginal log-likelihood on the model.
Interpretable Dynamics Models for Data-Efficient Reinforcement Learning
M. Kaiser, C. Otte, T. Runkler, C. H. Ek
ESANN, 2019
Abstract
In this paper, we present a Bayesian view on model-based reinforcement learning. We use expert knowledge to impose structure on the transition model and present an efficient learning scheme based on variational inference. This scheme is applied to a heteroskedastic and bimodal benchmark problem on which we compare our results to NFQ and show how our approach yields human-interpretable insight about the underlying dynamics while also increasing data-efficiency.
Gaussian Process Latent Variable Alignment Learning
I. Kazlauskaite, C. H. Ek, N. D. F. Campbell
AISTATS, 2019
Abstract
We present a model that can automatically learn alignments between high-dimensional data in an unsupervised manner. Our proposed method casts alignment learning in a framework where both alignment and data are modelled simultaneously. Further, we automatically infer groupings of different types of sequence within the same dataset. We derive a probabilistic model built on non-parametric priors that allows for flexible warps while at the same time providing means to specify interpretable constraints. We demonstrate the efficacy of our approach with superior quantitative performance to the state-of-the-art approaches and provide examples to illustrate the versatility of our model in automatic inference of sequence groupings, absent from previous approaches, as well as easy specification of high level priors for different modalities of data.
2018
Bayesian Alignments of Warped Multi-Output Gaussian Processes
M. Kaiser, C. Otte, T. Runkler, C. H. Ek
Neural Information Processing Systems (NIPS), 2018
Abstract
We propose a novel Bayesian approach to modelling multimodal data generated by multiple independent processes, simultaneously solving the data association and induced supervised learning problems. Underpinning our approach is the use of Gaussian process priors which encode structure both on the functions and the associations themselves. The association of samples and functions are determined by taking both inputs and outputs into account while also obtaining a posterior belief about the relevance of the global components throughout the input space. We present an efficient learning scheme based on doubly stochastic variational inference and discuss how it can be applied to deep Gaussian process priors. We show results for an artificial data set, a noise separation problem, and a multimodal regression problem based on the cart-pole benchmark.
Active Learning Using Gaussian Processes for Imbalanced Datasets
Fariba Yousefi, Mauricio Alvarez, Carl Henrik Ek and Neil Lawrence
Neural Information Processing Systems (NIPS) Workshop on Bayesian Non-parametrics, 2018
Abstract
In this paper we address the imbalance problem in image classification using a combination of transfer learning from Convolutional Neural Networks (CNN) with Gaussian Process (GP) Classification. Manually labelling images is tedious and also image datasets can be expensive to label. In most cases, there are lots of data with no labels, and even if we have labels they are high-level labels. We consider a real-world example for image classification. The objective is to predict whether a pipe image consists of a clamp or not. We do not have the labels for the clamp itself but instead, some high-level labels which specifies if there is a clamp in the whole image or not. To overcome this difficulty our goal is to select data in a sensible manner and label fewer data so we can have efficient models with fewer labelled images. This will be achieved using active learning. The process starts with a small set of labelled data and continues by actively adding data from a pool of unlabelled data by manually labelling them. The proposed active learning method is able to use less data compared to other supervised learning approaches such as CNN. We compared the proposed method against CNN, Logistic Regression (LR) and random patch selection showing increased performance in terms of Recall and F1-Score.
Shape Modeling based on Sparse Gaussian Process Implicit Surfaces
Gabriela Zarzar Gandler, Carl Henrik Ek and Yasemin Bekiroglu
Neural Information Processing Systems (NIPS) Workshop Women in Machine Learning, 2018
Abstract
Sequence Alignment with Dirichlet Process Mixtures
I. Kazlauskaite, I. Ustyuzhaninov, C. H. Ek, N. D. F. Campbell
Neural Information Processing Systems (NIPS) Workshop on Bayesian Non-parametrics, 2018
Abstract
We present a probabilistic model for unsupervised alignment of high-dimensional time-warped sequences based on the Dirichlet Process Mixture Model (DPMM). We follow the approach introduced in (Kazlauskaite, 2018) of simultaneously representing each data sequence as a composition of a true underlying function and a time-warping, both of which are modelled using Gaussian processes (GPs) (Rasmussen, 2005), and aligning the underlying functions using an unsupervised alignment method. In (Kazlauskaite, 2018) the alignment is performed using the GP latent variable model (GP-LVM) (Lawrence, 2005) as a model of sequences, while our main contribution is extending this approach to using DPMM, which allows us to align the sequences temporally and cluster them at the same time. We show that the DPMM achieves competitive results in comparison to the GP-LVM on synthetic and real-world data sets, and discuss the different properties of the estimated underlying functions and the time-warps favoured by these models.
Bayesian Alignments of Warped Multi-Output Gaussian Processes
M. Kaiser, C. Otte, T. Runkler, C. H. Ek
Neural Information Processing Systems (NIPS), 2018
Abstract
We propose a novel Bayesian approach to modelling nonlinear alignments of time series based on latent shared information. We apply the method to the real-world problem of finding common structure in the sensor data of wind turbines introduced by the underlying latent and turbulent wind field. The proposed model allows for both arbitrary alignments of the inputs and non-parametric output warpings to transform the observations. This gives rise to multiple deep Gaussian process models connected via latent generating processes. We present an efficient variational approximation based on nested variational compression and show how the model can be used to extract shared information between dependent time series, recovering an interpretable functional decomposition of the learning problem. We show results for an artificial data set and real-world data of two wind turbines.
Gaussian Process Deep Belief Networks: A Smooth Generative Model of Shape with Uncertainty Propagation
A. di Martino, E. Bodin, C. H. Ek, N. D. Campbell
Asian Conference on Computer Vision, 2018
Abstract
The shape of an object is an important characteristic for many vision problems such as segmentation, detection and tracking. Being independent of appearance, it is possible to generalise to a large range of objects from only small amounts of data. However, shapes represented as silhouette images are challenging to model due to complicated likelihood functions leading to intractable posteriors. In this paper we present a generative model of shapes which provides allow dimensional latent encoding which importantly resides on a smooth manifold with respect to the silhouette images. The proposed model propagates uncertainty in a principled manner allowing it to learn from small amounts of data and providing predictions with associated uncertainty. We provide experiments that show how our proposed model provides favourable quantitative results compared with the state-of-the-art while simultaneously providing a representation that resides on a low-dimensional interpretable manifold.
Perceptual Facial Expression Representation
O. Mikheeva, C. H. Ek, H. Kjellstrom
IEEE International Conference on Automatic Face and Gesture Recognition, 2018
Abstract
Variational approximations are an attractive approach for inference of latent variables in unsupervised learning. However, they are often computationally intractable when faced with large datasets. Recently, Variational Autoencoders (VAEs) Kingma and Welling [2014] have been proposed as a method to tackle this limitation. Their methodology is based on formulating the approximating posterior distributions in terms of a deterministic relationship to observed data consequently the title “Auto-Encoding Variational Bayes”. Importantly, this is a decision regarding an approximate inference scheme that should not be confused with an auto-encoder as a model
2017
Abstract
Many tasks in robotics and computer vision are concerned with inferring a continuous or discrete state variable from observations and measurements from the environment. Due to the high-dimensional nature of the input data the inference is often cast as a two stage process: first a low-dimensional feature representation is extracted on which secondly a learning algorithm is applied. Due to the significant progress that have been achieved within the field of machine learning over the last decade focus have placed at the second stage of the inference process, improving the process by exploiting more advanced learning techniques applied to the same (or more of the same) data. We believe that for many scenarios significant strides in performance could be achieved by focusing on representation rather than aiming to alleviate inconclusive and/or redundant information by exploiting more advanced inference methods. This stems from the notion that; given the “correct” representation the inference problem becomes easier to solve. In this paper we argue that one important mode of information for many application scenarios is not the actual variation in the data but the rather the higher order statistics as the structure of variations. We will exemplify this through a set of applications and show different ways of representing the structure of data.
Latent Structure Learning using Gaussian and Dirichlet Processes
A. Lawrence, C. H. Ek and N.D.F. Campbell
NIPS Workshops, 2017
Abstract
Nonparametric Inference for Auto-Encoding Variational Bayes
E. Bodin, I. Malik, C. H. Ek and N.D.F. Campbell
NIPS Workshops, 2017
Abstract
Variational approximations are an attractive approach for inference of latent variables in unsupervised learning. However, they are often computationally intractable when faced with large datasets. Recently, Variational Autoencoders (VAEs) Kingma and Welling [2014] have been proposed as a method to tackle this limitation. Their methodology is based on formulating the approximating posterior distributions in terms of a deterministic relationship to observed data consequently the title “Auto-Encoding Variational Bayes”. Importantly, this is a decision regarding an approximate inference scheme that should not be confused with an auto-encoder as a model
Abstract
Music is an expressive form of communication often used to convey emotion in scenarios where words are not enough. Part of this information lies in the musical composition where well-defined language exists. However, a significant amount of information is added during a performance as the musician interprets the composition. The performer injects expressiveness into the written score through variations of different musical properties such as dynamics and tempo. In this paper, we describe a model that can learn to perform sheet music. Our research concludes that the generated performances are indistinguishable from a human performance, thereby passing a test in the spirit of a musical Turing test
2016
Learning warpings from latent space structures
I. Kazlauskaite, C. H. Ek, N. Campbell
NIPS, Workshop on Learning in High-dimensions with Structure, 2016
Abstract
Unsupervised Learning with Imbalanced Data via Structure Consolidation Latent Variable Model
F. Yousefi, Z. Dai, C. H. Ek, N. D. Lawrence
International Conference on Learning Representations, Workshop-track, 2016
Abstract
Unsupervised learning on imbalanced data is challenging because, when given imbalanced data, current model is often dominated by the major category and ignores the categories with small amount of data. We develop a latent variable model that can cope with imbalanced data by dividing the latent space into a shared space and a private space. Based on Gaussian Process Latent Variable Models, we propose a new kernel formulation that enables the separation of latent space and derives an efficient variational inference method. The performance of our model is demonstrated with an imbalanced medical image dataset.
Diagnostic Prediction Using Discomfort Drawings with IBTM
C. Zhang, H. Kjellstrom, C. H. Ek, B C. Bertilson
Machine Learning and Healthcare Conference, 2016
Abstract
In this paper, we explore the possibility to apply machine learning to make diagnostic predictions using discomfort drawings. A discomfort drawing is an intuitive way for patients to express discomfort and pain related symptoms. These drawings have proven to be an effective method to collect patient data and make diagnostic decisions in real-life practice. A dataset from real-world patient cases is collected for which medical experts provide diagnostic labels. Next, we use a factorized multimodal topic model, Inter-Battery Topic Model (IBTM), to train a system that can make diagnostic predictions given an unseen discomfort drawing. The number of output diagnostic labels is determined by using mean-shift clustering on the discomfort drawing. Experimental results show reasonable predictions of diagnostic labels given an unseen discomfort drawing. Additionally, we generate synthetic discomfort drawings with IBTM given a diagnostic label, which results in typical cases of symptoms. The positive result indicates a significant potential of machine learning to be used for parts of the pain diagnostic process and to be a decision support system for physicians and other health care personnel.
Active Exploration Using Gaussian Random Fields and Gaussian Process Implicit Surfaces
S Caccamo, Y Bekiroglu, C H Ek, D Kragic
IEEE/RJS International Conference on Intelligent Robots and Systems, 2016
Abstract
In this work we study the problem of exploring surfaces and building compact 3D representations of the environment surrounding a robot through active perception. We propose an online probabilistic framework that merges visual and tactile measurements using Gaussian Random Field and Gaussian Process Implicit Surfaces. The system investigates incomplete point clouds in order to find a small set of regions of interest which are then physically explored with a robotic arm equipped with tactile sensors. We show experimental results obtained using a PrimeSense camera, a Kinova Jaco2 robotic arm and Optoforce sensors on different scenarios. We then demostrate how to use the online framework for object detection and terrain classification.
Inter-Battery Topic Representation Learning
C. Zhan, H. Kjellström, C. H. Ek
European Conference on Computer Vision (ECCV), 2016
Abstract
In this paper, we present the Inter-Battery Topic Model (IBTM). Our approach extends traditional topic models by learning a factorized latent variable representation. The structured representation leads to a model that marries benefits traditionally associated with a discriminative approach, such as feature selection, with those of a generative model, such as principled regularization and ability to handle missing data. The factorization is provided by representing data in terms of aligned pairs of observations as different views. This provides means for selecting a representation that separately models topics that exist in both views from the topics that are unique to a single view. This structured consolidation allows for efficient and robust inference and provides a compact and efficient representation. Learning is performed in a Bayesian fashion by maximizing a rigorous bound on the log-likelihood. Firstly, we illustrate the benefits of the model on a synthetic dataset,. The model is then evaluated in both uni- and multi-modality settings on two different classification tasks with off-the-shelf convolutional neural network (CNN) features which generate state-of-the-art results with extremely compact representations.
Probabilistic consolidation of grasp experience
Y Bekiroglu, A Damianou, R Detry, J. A. Stork, D Kragic, C. H. Ek
IEEE International Conference on Robotics and Automation (ICRA), 2016
Abstract
We present a probabilistic model for joint representation of several sensory modalities and action parameters in a robotic grasping scenario. Our non-linear probabilistic latent variable model encodes relationships between grasp-related parameters, learns the importance of features, and expresses confidence in estimates. The model learns associations between stable and unstable grasps that it experiences during an exploration phase. We demonstrate the applicability of the model for estimating grasp stability, correcting grasps, identifying objects based on tactile imprints and predicting tactile imprints from object-relative gripper poses. We performed experiments on a real platform with both known and novel objects, i.e., objects the robot trained with, and previously unseen objects. Grasp correction had a 75% success rate on known objects, and 73% on new objects. We compared our model to a traditional regression model that succeeded in correcting grasps in only 38% of cases.
2015
The Path Kernel: A Novel Kernel for Sequential Data
A. Baisero, F. T. Pokorny and C. H. Ek
Pattern Recognition Applications and Methods, 2015

Abstract
We define a novel kernel function for finite sequences of arbitrary length which we call the path kernel. We evaluate this kernel in a classification scenario using synthetic data sequences and show that our kernel can outperform state of the art sequential similarity measures. Furthermore, we find that, in our experiments, a clustering of data based on the path kernel results in much improved interpretability of such clusters compared to alternative approaches such as dynamic time warping or the global alignment kernel.
Task-based Robot Grasp Planning using Probabilistic Inference
D. Song, C. H. Ek, K. Huebner, and D. Kragic
IEEE Transactions on Robotics, 2015
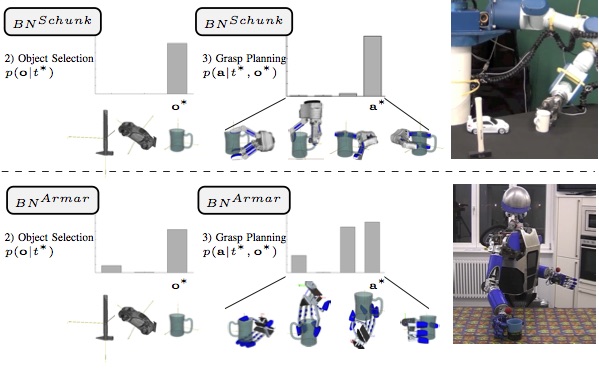
Abstract
Grasping and manipulation of everyday objects in a goal-directed manner is an important ability of a service robot. The robot needs to reason about task requirements and ground these in the sensorimotor information. Grasping and interaction with objects are challenging in real-world scenarios where sensorimotor uncertainty is prevalent. This paper presents a probabilistic framework for representation and modeling of robot grasping tasks. The framework consists of Gaussian mixture models for generic data discretization, and discrete Bayesian networks for encoding the probabilistic relations among various task-relevant variables including object and action features as well as task constraints. We evaluate the framework using a grasp database generated in a simulated environment including a human and two robot hand models. The generative modeling approach allows prediction of grasping tasks given uncertain sensory data, as well as object and grasp selection in a task-oriented manner. Furthermore, the graphical model framework provides insights into dependencies between variables and features relevant for object grasping.
Manifold Alignment Determination
A. Damianou, N. Lawrence, C. Ek
NIPS workshop on Multi-Modal Machine Learning, 2015
Abstract
We present Manifold Alignment Determination (MAD), an algorithm for learningalignments between data points from multiple views or modalities. The approachis capable of learning correspondences between views as well as correspondencesbetween individual data-points. The proposed method requires only a few alignedexamples from which it is capable to recover a global alignment through a probabilisticmodel. The strong, yet flexible regularization provided by the generativemodel is sufficient to align the views. We provide experiments on both synthetic and real data to highlight the benefit of the proposed approach.
Learning Predictive State Representation for In-Hand Manipulation
J. A. Stork, C. H. Ek, Y. Bekiroğlu, and D. Kragic
IROS, 2015
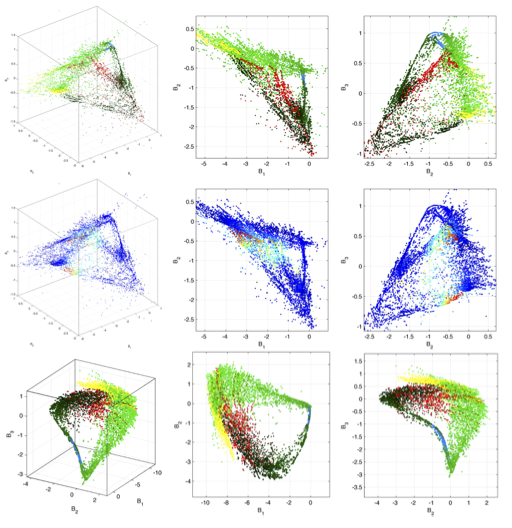
Abstract
We study the use of Predictive State Representation (PSR) for modeling of an in-hand manipulation task through interaction with the environment. We extend the original PSR model to a new domain of in-hand manipulation and address the problem of partial observability by introducing new kernel- based features that integrate both actions and observations. The model is learned directly from haptic data and is used to plan series of actions that rotate the object in the hand to a specific configuration by pushing it against a table. Further, we analyze the model’s belief states using additional visual data and enable planning of action sequences when the observations are ambiguous. We show that the learned representation is geo- metrically meaningful by embedding labeled action-observation traces. Suitability for planning is demonstrated by a post-grasp manipulation example that changes the object state to multiple specified target configurations.
A top-down approach for a synthetic autobiographical memory system
A Damianou, C. H. Ek, L Boorman, ND Lawrence, TJ Prescott
Conference on Biomimetic and Biohybrid Systems, 2015
Abstract
Autobiographical memory (AM) refers to the organisation of one’s experience into a coherent narrative. The exact neural mechanisms responsible for the manifestation of AM in humans are unknown. On the other hand, the field of psychology has provided us with useful understanding about the functionality of a bio-inspired synthetic AM (SAM) system, in a higher level of description. This paper is concerned with a top-down approach to SAM, where known components and organisation guide the architecture but the unknown details of each module are abstracted. By using Bayesian latent variable models we obtain a transparent SAM system with which we can interact in a structured way. This allows us to reveal the properties of specific sub-modules and map them to functionality observed in biological systems. The top-down approach can cope well with the high performance requirements of a bio-inspired cognitive system. This is demonstrated in experiments using faces data.
Learning Human Priors for Task-Constraints Grasping
M. Hjelm, R. Detry, C. H. Ek, D. Kragic
International Conference on Vision Systems, 2015

Abstract
In this paper we formulate task based robotic grasping as a feature learning problem. Using a human demonstrator to provide examples of grasps associatedwith a specific task we learn a representation where similarity in task is reflected by similarity in feature. Grasps for an observed task can besynthesized, on previously unseen objects, by matching to learned instances in the transformed feature space. We show on a real robot how our approach is able to synthesize task specific grasps using previously observed instances of task specific grasps.
Persistent evidence of local image properties in generic convnets
A. S Razavian, H Azizpour, A Maki, J Sullivan, C. H. Ek, S Carlsson
Scandinavian Conference on Image Analysis, 2015
Abstract
Supervised training of a convolutional network for object classification should make explicit any information related to the class of objects and disregard any auxiliary information associated with the capture of the image or the variation within the object class. Does this happen in practice? Although this seems to pertain to the very final layers in the network, if we look at earlier layers we find that this is not the case. In fact, strong spatial information is implicit. This paper addresses this, in particular, exploiting the image representation at the first fully connected layer, i.e. the global image descriptor which has been recently shown to be most effective in a range of visual recognition tasks. We empirically demonstrate evidences for the finding in the contexts of four different tasks: 2d landmark detection, 2d object keypoints prediction, estimation of the RGB values of input image, and recovery of semantic label of each pixel. We base our investigation on a simple framework with ridge rigression commonly across these tasks, and show results which all support our insight. Such spatial information can be used for computing correspondence of landmarks to a good accuracy, but should potentially be useful for improving the training of the convolutional nets for classification purposes.
Learning Predictive State Representations for Planning
J. A. Stork, C. H. Ek, Y Bekiroglu, D Kragic
IEEE/RSJ International Conference on Intelligent Robots and Systems, 2015
Abstract
Predictive State Representations (PSRs) allow modeling of dynamical systems directly in observables and without relying on latent variable representations. A problem that arises from learning PSRs is that it is often hard to attribute semantic meaning to the learned representation. This makes generalization and planning in PSRs challenging. In this paper, we extend PSRs and introduce the notion of PSRs that include prior information (P-PSRs) to learn representations which are suitable for planning and interpretation. By learning a low-dimensional embedding of test features we map belief points of similar semantic to the same region of a subspace. This facilitates better generalization for planning and semantical interpretation of the learned representation. In specific, we show how to overcome the training sample bias and introduce feature selection such that the resulting representation emphasizes observables related to the planning task. We show that our P-PSRs result in qualitatively meaningful representations and present quantitative results that indicate improved suitability for planning.
2014
Comparing distributions of color words: pitfalls and metric choices
M.Vejdemo-Johansson, S. Vejdemo, C.H. Ek
Public Library of Science PLOS One, 2014
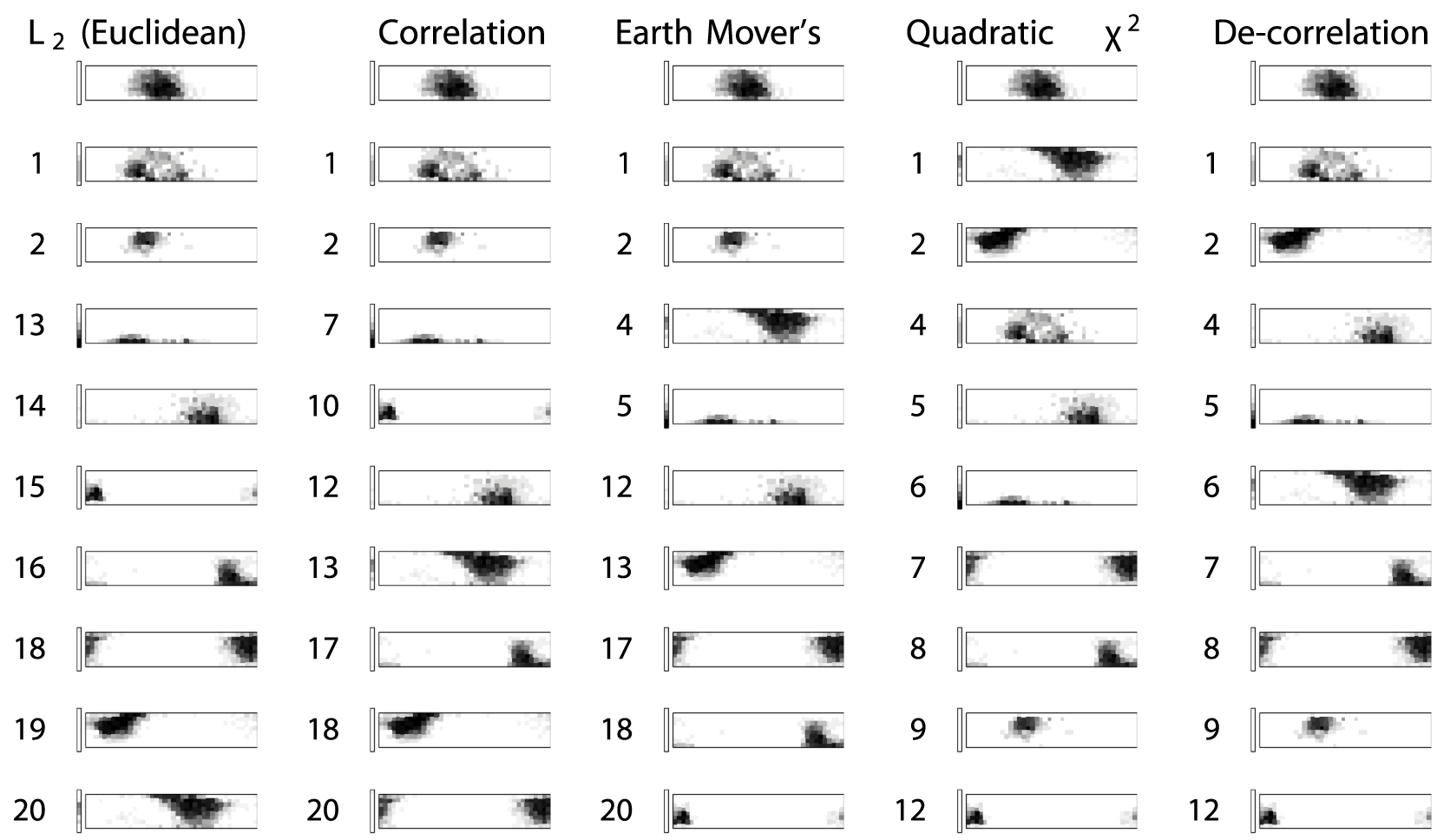
Abstract
Computational methods have started playing a significant role in semantic analysis. One particularly accessible area for developing good computationalmethods for linguistic semantics is in color naming, where perceptual dissimilarity measures provide a geometric setting for the analyses. This setting hasbeen studied first by Berlin & Kay in 1969, and then later on by a large data collection effort: the World Color Survey (WCS). From the WCS, a dataset oncolor naming by 2 616 speakers of 110 different languages is made available for further research. In the analysis of color naming from WCS, however, thechoice of analysis method is an important factor of the analysis. We demonstrate concrete problems with the choice of metrics made in recent analyses of WCSdata, and offer approaches for dealing with the problems we can identify. Picking a metric for the space of color naming distributions that ignoresperceptual distances between colors assumes a decorrelated system, where strong spatial correlations in fact exist. We can demonstrate that thecorresponding issues are significantly improved when using Earth Mover’s Distance, or Quadratic x-square Distance, and we can approximate these solutions with a kernel-based analysis method.
Learning Object, Grasping and Manipulation Activities using Hierarchical HMMs
M. Patel, J. V. Miro, D. Kragic, C. H. Ek, and G. Dissanayake
Autonomous Robots, 2014

Abstract
This article presents a probabilistic algorithm for representing and learning complex manipulation activities performed by humans in everyday life. The work builds on the multi-level Hierarchical Hidden Markov Model (HHMM) framework which allows decomposition of longer-term complex manipulation activities into layers of abstraction whereby the building blocks can be represented by simpler action modules called action primitives. This way, human task knowledge can be synthesised in a compact, effective representation suitable, for instance, to be subsequently transferred to a robot for imitation. The main contribution is the use of a robust framework capable of dealing with the uncertainty or incomplete data inherent to these activities, and the ability to represent behaviours at multiple levels of abstraction for enhanced task generalisation. Activity data from 3D video sequencing of human manipulation of different objects handled in everyday life is used for evaluation. A comparison with a mixed generative-discriminative hybrid model HHMM/SVM (support vector machine) is also presented to add rigour in highlighting the benefit of the proposed approach against comparable state of the art techniques.
Recognizing Object Affordances in Terms of Spatio-Temporal Object-Object Relationships
A. Pieropan, C. H. Ek, and H. Kjellström
IEEE-RAS International Conference on Humanoid Robots, 2014
Abstract
In this paper we describe a probabilistic framework that models the interaction between multiple objects in a scene. We present a spatio-temporal feature encoding pairwise interactions between each object in the scene. By the use of a kernel representation we embed object interactions in a vector space which allows us to define a metric comparing interactions of different temporal extent. Using this metric we define a probabilistic model which allows us to represent and extract the affordances of individual objects based on the structure of their interaction. In this paper we focus on the presented pairwise relationships but the model can naturally be extended to incorporate additional cues related to a single object or multiple objects. We compare our approach with traditional kernel approaches and show a significant improvement.
A topological framework for training Latent Variable Models
H. M. Afkham, C. H. Ek, and S. Carlsson
International Conference on Pattern Recognition, 2014
Abstract
We discuss the properties of a class of latent variable models that assumes each labeled sample is associated with a set of different features, with no prior knowledge of which feature is the most relevant feature to be used. Deformable-Part Models (DPM) can be seen as good examples of such models. These models are usually considered to be expensive to train and very sensitive to the initialization. In this paper, we focus on the learning of such models by introducing a topological framework and show how it is possible to both reduce the learning complexity and produce more robust decision boundaries. We will also argue how our framework can be used for producing robust decision boundaries without exploiting the dataset bias or relying on accurate annotations. To experimentally evaluate our method and compare with previously published frameworks, we focus on the problem of image classification with object localization. In this problem, the correct location of the objects is unknown, during both training and testing stages, and is considered as a latent variable.
Representations for Cross-task, Cross-object Grasp Transfer
M. Hjelm, R. Detry, C. H. Ek, and D. Kragic
IEEE International Conference on Robotics and Automation, 2014
Abstract
We address the problem of transferring grasp knowledge across objects and tasks. This means dealing with two important issues: 1) the induction of possible transfers, i.e., whether a given object affords a given task, and 2) the planning of a grasp that will allow the robot to fulfill the task. The induction of object affordances is approached by abstracting the sensory input of an object as a set of attributes that the agent can reason about through similarity and proximity. For grasp execution, we combine a part-based grasp planner with a model of task constraints. The task constraint model indicates areas of the object that the robot can grasp to execute the task. Within these areas, the part-based planner finds a hand placement that is compatible with the object shape. The key contribution is the ability to transfer task parameters across objects while the part-based grasp planner allows for transferring grasp information across tasks. As a result, the robot is able to synthesize plans for previously unobserved task/object combinations. We illustrate our approach with experiments conducted on a real robot.
Initialization framework for latent variable models
H. M. Afkham, C. H. Ek, and S. Carlsson
International Conference on Pattern Recognition Applications and Methods, 2014
Abstract
In this paper, we discuss the properties of a class of latent variable models that assumes each labeled sample is associated with set of different features, with no prior knowledge of which feature is the most relevant feature to be used. Deformable-Part Models (DPM) can be seen as good example of such models. While Latent SVM framework (LSVM) has proven to be an efficient tool for solving these models, we will argue that the solution found by this tool is very sensitive to the initialization. To decrease this dependency, we propose a novel clustering procedure, for these problems, to find cluster centers that are shared by several sample sets while ignoring the rest of the cluster centers. As we will show, these cluster centers will provide a robust initialization for the LSVM framework.
Gradual improvement of image descriptor quality
H. M. Afkham, C. H. Ek, and S. Carlsson
International Conference on Pattern Recognition Applications and Methods, 2014
Abstract
In this paper, we propose a framework to gradually improve the quality of an already existing image descriptor. The descriptor used in this paper uses the response of a series of discriminative components for summarizing each image. As we will show, this descriptor has an ideal form in which all categories become linearly separable. While, reaching this form is not feasible, we will argue by replacing a small fraction of the components, it is possible to obtain a descriptor which is, on average, closer to this ideal form. To do so, we identify which components do not contribute to the quality of the descriptor and replace them with more robust components. Here, a joint feature selection method is used to find more robust components. As our experiments show, this change directly reflects in the capability of the resulting descriptor in discriminating between different categories.
2013
Extracting Postural Synergies for Robotic Grasping
J. Romero, T. Feix, C. H. Ek, H. Kjellström, and D. Kragic
IEEE Transactions on Robotics, 2013
Abstract
We address the problem of representing and encoding human hand motion data using nonlinear dimensionality reduction methods. We build our work on the notionof postural synergies being typically based on a linear embedding of the data. In addition to addressing the encoding of postural synergies using nonlinearmethods, we relate our work to control strategies of combined reaching and grasping movements. We show the drawbacks of the (commonly made) causalityassumption and propose methods that model the data as being generated from an inferred latent mani- fold to cope with the problem. Another importantcontribution is a thorough analysis of the parameters used in the employed dimen- sionality reduction techniques. Finally, we provide an experimental evaluation that shows how the proposed methods outperform the standard techniques, both in terms of recognition and generation of motion patterns.
Non-Parametric Hand Pose Estimation with Object Context
J. Romero, H. Kjellström, C. H. Ek, and D. Kragic
Image and Vision, 2013
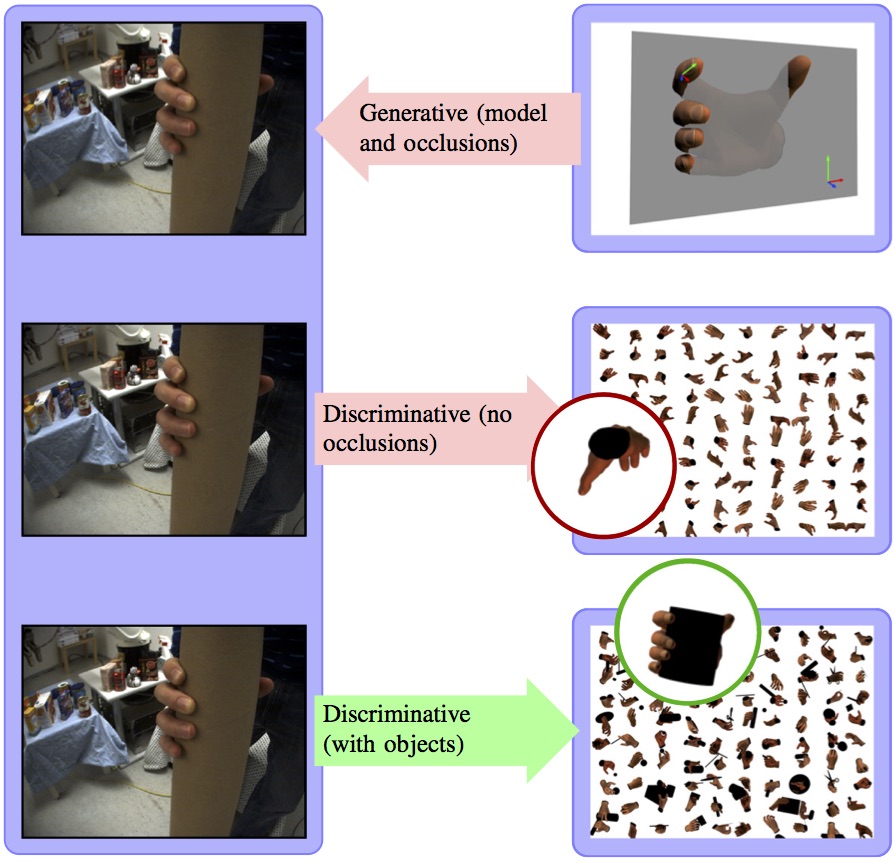
Abstract
In the spirit of recent work on contextual recognition and estimation, we present a method for estimating the pose of human hands, employing informationabout the shape of the object in the hand. Despite the fact that most applications of human hand tracking involve grasping and manipulation of objects, themajority of methods in the literature assume a free hand, isolated from the surrounding environment. Occlusion of the hand from grasped objects does in factoften pose a severe challenge to the estimation of hand pose. In the presented method, object occlusion is not only compensated for, it contributes to thepose estimation in a contextual fashion; this without an explicit model of object shape. Our hand tracking method is non-parametric, performing a nearestneighbor search in a large database (.. entries) of hand poses with and without grasped objects. The system that operates in real time, is robust to selfocclusions, object occlu- sions and segmentation errors, and provides full hand pose reconstruction from monocular video. Temporal consistency in hand poseis taken into account, without explicitly tracking the hand in the high-dim pose space. Experiments show the non-parametric method to outperform other state of the art regression methods, while operating at a significantly lower computational cost than comparable model-based hand tracking methods.
Supervised Hierarchical Dirichlet Processwith Variational Inference
C. Zhang, C. H. Ek, X. Gratal, F. T. Pokorny, and H. Kjellström
ICCV Workshop on Graphical Models and Inference, 2013
Abstract
We present an extension to the Hierarchical Dirichlet Process (HDP), which allows for the inclusion of supervision. Our model marries the non-parametric benefits of HDP with those of Supervised Latent Dirichlet Allocation (SLDA) to enable learning the topic space directly from data while simultaneously including the labels within the model. The proposed model is learned using variational inference which allows for the efficient use of a large training dataset. We also present the online version of variational inference, which makes the method scalable to very large datasets. We show results comparing our model to a traditional supervised parametric topic model, SLDA, and show that it outperforms SLDA on a number of benchmark datasets.
Extracting Essential Local Object Characteristics for 3D Object Categorization
M. Madry, H. M. Afkham, C. H. Ek, S. Carlsson, and D. Kragic
IEEE/RSJ International Conference on Intelligent Robots and Systems, 2013
Abstract
Most object classes share a considerable amount of local appearance and often only a small number of features are discriminative. The traditional approach to represent an object is based on a summarization of the local characteristics by counting the number of feature occurrences. In this paper we propose the use of a recently developed technique for summarizations that, rather than looking into the quantity of features, encodes their quality to learn a description of an object. Our approach is based on extracting and aggregating only the essential characteristics of an object class for a task. We show how the proposed method significantly improves on previous work in 3D object categorization. We discuss the benefits of the method in other scenarios such as robot grasping. We provide extensive quantitative and qualitative experiments comparing our approach to the state of the art to justify the described approach.
Sparse summarization of robotic grasp data
M. Hjelm, C. H. Ek, R. Detry, H. Kjellström and D. Kragic
IEEE International Conference on Robotics and Automation, 2013
Abstract
We propose a new approach for learning a summarized representation of high dimensional continuous data. Our technique consists of a Bayesian non-parametric model capable of encoding high-dimensional data from complex distributions using a sparse summarization. Specifically, the method marries techniques from probabilistic dimensionality reduction and clustering. We apply the model to learn efficient representations of grasping data for two robotic scenarios.
Generalizing Task Parameters Through Modularization
R. Detry, M. Hjelm, C. H. Ek, and D. Kragic
International Conference on Robotics and Automation Workshop on Autonomous Learning, 2013
Abstract
We address the problem of generalizing manipulative actions across different tasks and objects. Our robotic agent acquires task-oriented skills from a teacher, and it abstracts skill parameters away from the specificity of the objects and tools used by the teacher. This process enables the transfer of skills to novel objects. Our method relies on the modularization of a task’s representation. Through modularization, we associate each action parameter to a narrow visual modality, therefore facilitating transfers across different objects or tasks. We present a simple experiment where the robot transfers task parameters across three tasks and three objects.
Qualitative Vocabulary based Descriptor
H. M. Afkham, C. H. Ek, S Carlsson
International Conference on Pattern Recognition Applications and Methods, 2013
Abstract
Creating a single feature descriptors from a collection of feature responses is an often occurring task. As such the bag-of-words descriptors have been very successful and applied to data from a large range of different domains. Central to this approach is making an association of features to words. In this paper we present a new and novel approach to feature to word association problem. The proposed method creates a more robust representation when data is noisy and requires less words compared to the traditional methods while retaining similar performance. We experimentally evaluate the method on a challenging image classification data-set and show significant improvement to the state of the art.
Language for Learning Complex Human-Object Interactions
M. Patel, C. H. Ek, N. Kyriazis, A. Argyros, J. V. Miro, D. Kragic
IEEE International Conference on Robotics and Automation, 2013
Abstract
In this paper we use a Hierarchical Hidden Markov Model (HHMM) to represent and learn complex activities/task performed by humans/robots in everyday life. Action primitives are used as a grammar to represent complex human behaviour and learn the interactions and behaviour of human/robots with different objects. The main contribution is the use of a probabilistic model capable of representing behaviours at multiple levels of abstraction to support the proposed hypothesis. The hierarchical nature of the model allows decomposition of the complex task into simple action primitives. The framework is evaluated with data collected for tasks of everyday importance performed by a human user.
Learning a Dictionary of Prototypical Grasp-predicting Parts from Grasping Experience
R. Detry, C. H. Ek, M. Madry, J. Piater, D. Kragic
IEEE International Conference on Robotics and Automation, 2013
Abstract
We present a real-world robotic agent that is capable of transferring grasping strategies across objects that share similar parts. The agent transfers grasps across objects by identifying, from examples provided by a teacher, parts by which objects are often grasped in a similar fashion. It then uses these parts to identify grasping points onto novel objects. We focus our report on the definition of a similarity measure that reflects whether the shapes of two parts resemble each other, and whether their associated grasps are applied near one another. We present an experiment in which our agent extracts five prototypical parts from thirty-two real-world grasp examples, and we demonstrate the applicability of the prototypical parts for grasping novel objects.
Functional Object Descriptors for Human Activity Modeling
A. Pieropan, C. H. Ek and H. Kjellström
IEEE International Conference on Robotics and Automation, 2013
Abstract
The ability to learn from human demonstration is essential for robots in human environments. The activity models that the robot builds from observation must take both the human motion and the objects involved into account. Object models designed for this purpose should reflect the role of the object in the activity - its function, or affordances. The main contribution of this paper is to represent object directly in terms of their interaction with human hands, rather than in terms of appearance. This enables the direct representation of object affordances/function, while being robust to intra-class differences in appearance. Object hypotheses are first extracted from a video sequence as tracks of associated image segments. The object hypotheses are encoded as strings, where the vocabulary corresponds to different types of interaction with human hands. The similarity between two such object descriptors can be measured using a string kernel. Experiments show these functional descriptors to capture differences and similarities in object affordances/function that are not represented by appearance.
Factorized Topic Models
C. Zhang, C. H. Ek, and H. Kjellström
International Conference on Representation Learning, 2013
Abstract
In this paper we present a modification to a latent topic model, which makes the model exploit supervision to produce a factorized representation of the observed data. The structured parameterization separately encodes variance that is shared between classes from variance that is private to each class by the introduction of a new prior over the topic space. The approach allows for a more eff{}icient inference and provides an intuitive interpretation of the data in terms of an informative signal together with structured noise. The factorized representation is shown to enhance inference performance for image, text, and video classification.
Inferring Hand Pose: A Comparative Study
A. T. Sridatta, C. H. Ek, H. Kjellström
IEEE International Conference on Automatic Face and Gesture Recognition, 2013
Abstract
Hand pose estimation from video is essential for a number of applications such as automatic sign language recognition and robot learning from demonstration. However, hand pose estimation is made difficult by the high degree of articulation of the hand; a realistic hand model is described with at least 35 dimensions, which means that it can assume a wide variety of poses, and there is a very high degree of self occlusion for most poses. Furthermore, different parts of the hand display very similar visual appearance; it is difficult to tell fingers apart in video. These properties of hands put hard requirements on visual features used for hand pose estimation and tracking. In this paper, we evaluate three different state-of-the-art visual shape descriptors, which are commonly used for hand and human body pose estimation. We study the nature of the mappings from the hand pose space to the feature spaces spanned by the visual descriptors, in terms of the smoothness, discriminability, and generativity of the pose-feature mappings, as well as their robustness to noise in terms of these properties. Based on this, we give recommendations on in which types of applications each visual shape descriptor is suitable.
The Path Kernel
A. Baisero, F. T. Pokorny , D. Kragic, C. H. Ek
International Conference on Pattern Recognition Applications and Methods, 2013
Abstract
Kernel methods have been used very successfully to classify data in various application domains. Traditionally, kernels have been constructed mainly for vectorial data defined on a specific vector space. Much less work has been addressing the development of kernel functions for non-vectorial data. In this paper, we present a new kernel for encoding sequential data. We present our results comparing the proposed kernel to the state of the art, showing a significant improvement in classification and a much improved robustness and interpretability.
2012
A Metric for Comparing the Anthropomorphic Motion Capability of Artificial Hands
T. Feix, J. Romero, C. H. Ek, H. B. Schmiedmayer, and D. Kragic
IEEE Transactions on Robotics, 2012

Abstract
We propose a metric for comparing the anthropomorphic motion capability of robotic and prosthetic hands. The metric is based on the evaluation of how manydifferent postures or con- figurations a hand can perform by studying the reachable set of fingertip poses. To define a benchmark for comparison, we firstgenerate data with human subjects based on an extensive grasp taxonomy. We then develop a methodology for comparison using generative, nonlineardimensionality reduction techniques. We as- sess the performance of different hands with respect to the human hand and with respect to each other. The method can be used to compare other types of kinematic structures.
Persistent Homology for Learning Densities with Bounded Support
F. T. Pokorny , C. H. Ek, H. Kjellström, D. Kragic
Neural Information Processing Systems, 2012
Abstract
We present a novel method for learning densities with bounded support which enables us to incorporate ‘hard’ topological constraints. In particular, we show how emerging techniques from computational algebraic topology and the notion of persistent homology can be combined with kernel-based methods from machine learning for the purpose of density estimation. The proposed formalism facilitates learning of models with bounded support in a principled way, and – by incorporating persistent homology techniques in our approach – we are able to encode algebraic-topological constraints which are not addressed in current state of the art probabilistic models. We study the behaviour of our method on two synthetic examples for various sample sizes and exemplify the benefits of the proposed approach on a real-world dataset by learning a motion model for a race car. We show how to learn a model which respects the underlying topological structure of the racetrack, constraining the trajectories of the car.
Topological Constraints and Kernel based Density Estimation
F. T. Pokorny , C. H. Ek, H. Kjellström, D. Kragic
Neural Information Processing Systems Workshop on Algebraic Topology and Machine Learning, 2012
Abstract
This extended abstract1 explores the question of how to estimate a probability distribution from a finite number of samples when information about the topology of the support region of an underlying density is known. This workshop contribution is a continuation of our recent work [1] combining persistent homology and kernel-based density estimation for the first time and in which we explored an approach capable of incorporating topological constraints in bandwidth selection. We report on some recent experiments with high-dimensional motion capture data which show that our method is applicable even in high dimensions and develop our ideas for potential future applications of this framework.
“On-line Learning of Temporal State Models for Flexible Objects
N. Bergström, C. H. Ek, D. Kragic, Y. Yamakawa, T. Senoo, M. Ishikawa
IEEE-RAS International Conference on Humanoid Robotics, 2012
Abstract
State estimation and control are intimately related processes in robot handling of flexible and articulated objects. While for rigid objects, we can generate a CAD model beforehand and a state estimation boils down to estimation of pose or velocity of the object, in case of flexible and articulated objects, such as a cloth, the representation of the object's state is heavily dependent on the task and execution. For example, when folding a cloth, the representation will mainly depend on the way the folding is executed. In this paper, we address the problem of learning a temporal object model from observations generated during task execution. We use the case of dynamic cloth folding as a proof-of-concept for our methodology. In cloth folding, the most important information is contained in the temporal structure of the data requiring appropriate representation of the observations, fast state estimation and a suitable prediction mechanism. Our approach is realized through efficient implementation of feature extraction and a generative process model, exploiting recent hardware advances in conjunction with principled probabilistic models. The model is capable of representing the temporal structure of the data and it is robust to noise in the observations. We present results exploiting our model to classify the success of a folding action.
Improved Generalization for 3D Object Categorization with Global Structure Histogram
_M. Madry, C. H. Ek, R. Detry, K. Hang, D. Kragic
IEEE/RSJ International Conference on Intelligent Robots and Systems, 2012
Abstract
We propose a new object descriptor for three dimensional data named the Global Structure Histogram (GSH). The GSH encodes the structure of a local feature response on a coarse global scale, providing a beneficial trade-off between generalization and discrimination. Encoding the structural characteristics of an object allows us to retain low local variations while keeping the benefit of global representativeness. In an extensive experimental evaluation, we applied the framework to category-based object classification in realistic scenarios. We show results obtained by combining the GSH with several different local shape representations, and we demonstrate significant improvements to other state-of-the-art global descriptors.
Manifold Relevance Determination
A. Damianou, C. H. Ek, M. Titsias, N. D. Lawrence
International Conference on Machine Learning, 2012
Abstract
In this paper we present a fully Bayesian latent variable model which exploits conditional nonlinear (in)-dependence structures to learn an efficient latent representation. The latent space is factorized to represent shared and private information from multiple views of the data. In contrast to previous approaches, we introduce a relaxation to the discrete segmentation and allow for a “softly” shared latent space. Further, Bayesian techniques allow us to automatically estimate the dimensionality of the latent spaces. The model is capable of capturing structure underlying extremely high dimensional spaces. This is illustrated by modelling unprocessed images with tenths of thousands of pixels. This also allows us to directly generate novel images from the trained model by sampling from the discovered latent spaces. We also demonstrate the model by prediction of human pose in an ambiguous setting. Our Bayesian framework allows us to perform disambiguation in a principled manner by including latent space priors which incorporate the dynamic nature of the data
Generalizing Grasps Across Partly Similar Objects
R. Detry, C. H. Ek, M. Madry, J. Piater, D. Kragic
IEEE International Conference on Robotics and Automation, 2012
Abstract
The paper starts by reviewing the challenges associated to grasp planning, and previous work on robot grasping. Our review emphasizes the importance of agents that generalize grasping strategies across objects, and that are able to transfer these strategies to novel objects. In the rest of the paper, we then devise a novel approach to the grasp transfer problem, where generalization is achieved by learning, from a set of grasp examples, a dictionary of object parts by which objects are often grasped. We detail the application of dimensionality reduction and unsupervised clustering algorithms to the end of identifying the size and shape of parts that often predict the application of a grasp. The learned dictionary allows our agent to grasp novel objects which share a part with previously seen objects, by matching the learned parts to the current view of the new object, and selecting the grasp associated to the best-fitting part. We present and discuss a proof-of-concept experiment in which a dictionary is learned from a set of synthetic grasp examples. While prior work in this area focused primarily on shape analysis (parts identified, e.g., through visual clustering, or salient structure analysis), the key aspect of this work is the emergence of parts from both object shape and grasp examples. As a result, parts intrinsically encode the intention of executing a grasp.
”Robot give me something to drink from”: object representations for transferring task specific grasps
M. Madry, D. Song, C. H. Ek, D. Kragic
IEEE International Conference on Robotics and Automation, Workshop on Semantic Perception, Mapping and Exploration, 2012
Abstract
— In this paper, we present an approach for taskspecific object representation which facilitates transfer of grasp knowledge from a known object to a novel one. Our representation encompasses: (a) several visual object properties, (b) object functionality and (c) task constrains in order to provide a suitable goal-directed grasp. We compare various features describing complementary object attributes to evaluate the balance between the discrimination and generalization properties of the representation. The experimental setup is a scene containing multiple objects. Individual object hypotheses are first detected, categorized and then used as the input to a grasp reasoning system that encodes the task information. Our approach not only allows to find objects in a real world scene that afford a desired task, but also to generate and successfully transfer task-based grasp within and across object categories.
Model, Track and Analyse: Developments and Challenges in Understanding Facial Motion
A. Davies, C. Dalton, C. H. Ek and N. Campbell
Swedish Symposium on Automated Image Analysis, 2012
Abstract
NULL
Generating 3D Morphable Model Parameters for Facial Tracking: Factorising Identity and Expression
A. Davies, C. H. Ek, C. Dalton and N. Campbell
International Conference on Computer Graphics Theory and Applications, 2012
Abstract
The ability to factorise parameters into identity and expression parameters is highly desirable in facial tracking as it requires only the identity parameters to be set in the initial frame leaving the expression parameters to be adjusted in subsequent frames. In this paper we introduce a strategy for creating parameters for a data-driven 3D Morphable Model (3DMM) which are able to separately model the variance due to identity and expression found in the training data. We present three factorisation schemes and evaluate their appropriateness for tracking by comparing the variances between the identity coefficients and expression coefficients when fitted to data of individuals performing different facial expressions.
2011
Embodiment-specific representation of robot grasping using graphical models and latent-space discretization
D. Song, C. H. Ek, K. Huebner, and D. Kragic
IEEE/RSJ International Conference on Intelligent Robots and Systems, 2011
Abstract
We study embodiment-specific robot grasping tasks, represented in a probabilistic framework. The framework consists of a Bayesian network (BN) integrated with a novel multi-variate discretization model. The BN models the probabilistic relationships among tasks, objects, grasping actions and constraints. The discretization model provides compact data representation that allows efficient learning of the conditional structures in the BN. To evaluate the framework, we use a database generated in a simulated environment including examples of a human and a robot hand interacting with objects. The results show that the different kinematic structures of the hands affect both the BN structure and the conditional distributions over the modeled variables. Both models achieve accurate task classification, and successfully encode the semantic task requirements in the continuous observation spaces. In an imitation experiment, we demonstrate that the representation framework can transfer task knowledge between different embodiments, therefore is a suitable model for grasp planning and imitation in a goal-directed manner.
Multivariate discretization for bayesian network structure learning in robot grasping
D. Song, C. H. Ek, K. Huebner, and D. Kragic
IEEE International conference on robotics and automation, 2011
Abstract
A major challenge in modeling with BNs is learning the structure from both discrete and multivariate continuous data. A common approach in such situations is to discretize continuous data before structure learning. However efficient methods to discretize high-dimensional variables are largely lacking. This paper presents a novel method specifically aiming at discretization of high-dimensional, high-correlated data. The method consists of two integrated steps: non-linear dimensionality reduction using sparse Gaussian process latent variable models, and discretization by application of a mixture model. The model is fully probabilistic and capable to facilitate structure learning from discretized data, while at the same time retain the continuous representation. We evaluate the effectiveness of the method in the domain of robot grasping. Compared with traditional discretization schemes, our model excels both in task classification and prediction of hand grasp configurations. Further, being a fully probabilistic model it handles uncertainty in the data and can easily be integrated into other frameworks in a principled manner.
Representing actions with Kernels
G. Luo, N. Bergström, C. H. Ek, and D. Kragic
IEEE/RSJ International Conference on Intelligent Robots and Systems, 2012
Abstract
A long standing research goal is to create robots capable of interacting with humans in dynamic environments. To realise this a robot needs to understand and interpret the underlying meaning and intentions of a human action through a model of its sensory data. The visual domain provides a rich description of the environment and data is readily available in most system through inexpensive cameras. However, such data is very high-dimensional and extremely redundant making modeling challenging.
Scene understanding through autonomous interactive perception
N. Bergstrom, C. H. Ek, M.Björkman, and D. Kragic
International Conference on Computer Vision Systems, 2011
Abstract
We propose a framework for detecting, extracting and modeling objects in natural scenes from multi-modal data. Our framework is iterative, exploiting different hypotheses in a complementary manner. We employ the framework in realistic scenarios, based on visual appearance and depth information. Using a robotic manipulator that interacts with the scene, object hypotheses generated using appearance information are confirmed through pushing. The framework is iterative, each generated hypothesis is feeding into the subsequent one, continuously refining the predictions about the scene. We show results that demonstrate the synergic effect of applying multiple hypotheses for real-world scene understanding. The method is efficient and performs in real-time.
Learning Conditional Structures in Graphical Models from a Large Set of Observation Streams through efficient Discretisation
C. H. Ek, D. Song, and D. Kragic
IEEE International Conference on Robotics and Automation, Workshop on Manipulation under Uncertainty, 2011
Abstract
— The introduction of probabilistic graphical models to robotics research has been one of the success stories in the field over the last couple of years. Application of principles from statistical learning have allowed researchers to create systems which are aware and capable to reason about uncertainty in its observations. This has led to more robust and reliable systems. Many robotic applications are modeled from observations which are related by an underlying and unobserved conditional or casual relationship. One example of this is the study of affordances. Learning conditional structures from data has proved to be a tremendous challenge in the general case. Some progress have been made in special cases where the observations are discrete and low-dimensional. However, most interesting scenarios in robotics are characterized by high dimensional and continuous data. This means that for all but the simplest scenarios conditional structures had to be assumed in an ad-hoc manner and could not be learned from observations. In previous work [1] we have presented a method which allows for principled discretisation of continuous variables. In specific we applied this method in order to model the task of robotic grasping. In this paper we extends the work by introducing an additional prior into the model. The aim of this prior is to encourage an additional degree of sparseness in order to reduce the complexity of the discrete representation. Further, we also extend the learning domain by applying the model to a more challenging data-set, which further shows the benefits of the suggested approach.
State Recognition of Deformable Objects Using Shape Context
N. Bergström, Y. Yamakawa, T. Senoo, C. H. Ek, and M. Ishikawa
Annual Conference of the Robotics Society of Japan, 2011
Abstract
NULL
2010
Task Modeling in Imitation Learning using Latent Variable Models
C. H. Ek, D. Song, K. Huebner, and D. Kragic
IEEE-RAS International Conference on Humanoid Robotics, 2010
Abstract
An important challenge in robotic research is learning and reasoning about different manipulation tasks from scene observations. In this paper we present a probabilistic model capable of modeling several different types of input sources within the same model. Our model is capable to infer the task using only partial observations. Further, our framework allows the robot, given partial knowledge of the scene, to reason about what information streams to acquire in order to disambiguate the state-space the most. We present results for task classification within and also reason about different features discriminative power for different classes of tasks.
Exploring affordances in robot grasping through latent structure representation
C. H. Ek, D. Song, K. Huebner, and D. Kragic
European Conference on Computer Vision: Workshop on Vision for Cognitive Tasks, 2010
Abstract
An important challenge in robotic research is learning by imitation. The goal in such is to create a system whereby a robot can learn to perform a specific task by imitating a human instructor. In order to do so, the robot needs to determine the state of the scene through its sensory system. There is a huge range of possible sensory streams that the robot can make use of to reason and interact with its environment. Due to computational and algorithmic limitations we are interested in limiting the number of sensory inputs. Further, streams can be complementary both in general, but more importantly for specific tasks. Thereby, an intelligent and constrained limitation of the number of sensory inputs is motivated. We are interested in exploiting such structure in order to do what will be referred to as Goal-Directed-Perception (GDP). The goal of GDP is, given partial knowledge about the scene, to direct the robot’s modes of perception in order to maximally disambiguate the state space. In this paper, we present the application of two different probabilistic models in modeling the largely redundant and complementary observation space for the task of object grasping. We evaluate and discuss the results of both approaches.
“FOLS: Factorized Orthogonal Latent Spaces
M. Salzmann, C. H. Ek, R. Urtasun, and T. Darrell
Snowbird Learning Workshop, 2010
Abstract
Many machine learning problems inherently involve multiple views. Kernel combination approaches to multiview learning are particularly effective when the views are independent. In contrast, other methods take advantage of the dependencies in the data. The best-known example is Canonical Correlation Analysis (CCA), which learns latent representations of the views whose correlation is maximal. Unfortunately, this can result in trivial solutions in the presence of highly correlated noise. Recently, non-linear shared latent variable models that do not suffer from this problem have been proposed: the shared Gaussian process latent variable model (sGPLVM), and the shared kernel information embedding (sKIE). However, in real scenarios, information in the views is typically neither fully independent nor fully correlated. The few approaches that have tried to factorize the information into shared and private components are typically initialized with CCA, and thus suffer from its inherent weaknesses. In this paper, we propose a method to learn shared and private latent spaces that are inherently disjoint by introducing orthogonality constraints. Furthermore, we discover the structure and dimensionality of the latent representation of each data stream by encouraging it to be low dimensional, while still allowing to generate the data. Combined together, these constraints encourage finding factorized latent spaces that are non-redundant, and that can capture the shared-private separation of the data. We demonstrate the effectiveness of our approach by applying it to two existing models, the sGPLVM and the sKIE, and show significant performance improvement over the original models, as well as over the existing shared-private factorizations in the context of pose estimation.
Factorized Orthogonal Latent Spaces
M. Salzmann, C. H. Ek, R. Urtasun, and T. Darrell
International Conference on Artificial Intelligence and Statistics, 2010
Abstract
Existing approaches to multi-view learning are particularly effective when the views are either independent (i.e, multi-kernel approaches) or fully dependent (i.e., shared latent spaces). However, in real scenarios, these assumptions are almost never truly satisfied. Recently, two methods have attempted to tackle this problem by factorizing the information and learn separate latent spaces for modeling the shared (i.e., correlated) and private (i.e., independent) parts of the data. However, these approaches are very sensitive to parameters setting or initialization. In this paper we propose a robust approach to factorizing the latent space into shared and private spaces by introducing orthogonality constraints, which penalize redundant latent representations. Furthermore, unlike previous approaches, we simultaneously learn the structure and dimensionality of the latent spaces by relying on a regularizer that encourages the latent space of each data stream to be low dimensional. To demonstrate the benefits of our approach, we apply it to two existing shared latent space models that assume full dependence of the views, the sGPLVM and the sKIE, and show that our constraints improve the performance of these models on the task of pose estimation from monocular images.
2009
Shared Gaussian Process Latent Variable Models for Handling Ambiguous Facial Expressions
C. H. Ek, P. Jaeckel, N. Campbell, and C. Melhuish
Mediterranean Conference on Intelligent Systems and Automation,
Abstract
Despite the fact, that, in reality facial expressions occur as a result of muscle actions, facial expression models assume an inverse functional relationship, which makes muscles action be the result of facial expressions. Clearly, facial expression should be expressed as a function of muscle action, the other way around as previously suggested. Furthermore, a human facial expression space and the robots actuator space have common features. However, there are also features that the one or the other does not have. This suggests modelling shared and non‐shared feature variance separately. To this end we propose Shared Gaussian Process Latent Variable Models (Shared GP‐LVM) for models of facial expressions, which assume shared and private features between an input and output space. In this work, we are focusing on the detection of ambiguities within data sets of facial behaviour. We suggest ways of modelling and mapping of facial motion from a representation of human facial expressions to a robot’s actuator space. We aim to compensate for ambiguities caused by interference of global with local head motion and the constrained nature of Active Appearance Models, used for tracking.
2008
GP-LVM for Data Consolidation
C. H. Ek, P.H.S Torr, N. D. Lawrende
Neural Information Processing Systems: Workshop on Learning from multiple sources, 2008
Abstract
Many machine learning task are involved with the transfer of information from one representation to a corresponding representation or tasks where several different observations represent the same underlying phenomenon. A classical algorithm for feature selection using information from multiple sources or representations is Canonical Correlation Analysis (CCA). In CCA the objective is to select features in each observation space that are maximally correlated compared to dimension- ality reduction where the objective is to re-represent the d ata in a more efficient form. We suggest a dimensionality reduction technique that builds on CCA. By extending the latent space with two additional spaces, each specific to a partition of the data, the model is capable of representing the full var iance of the data. In this paper we suggest a generative model for shared dimensionality reduction analogous to that of CCA
Ambiguity modeling in latent spaces
C. H. Ek, J. Rihan, P. Torr, G. Rogez, and N. Lawrence
Machine Learning for Multimodal Interaction, 2008
Abstract
We are interested in the situation where we have two or more representations of an underlying phenomenon. In particular we are interested in the scenario where the representation are complementary. This implies that a single individual representation is not sufficient to fully discriminate a specific instance of the underlying phenomenon, it also means that each representation is an ambiguous representation of the other complementary spaces. In this paper we present a latent variable model capable of consolidating multiple complementary representations. Our method extends canonical correlation analysis by introducing additional latent spaces that are specific to the different representations, thereby explaining the full variance of the observations. These additional spaces, explaining representation specific variance, separately model the variance in a representation ambiguous to the other. We develop a spectral algorithm for fast computation of the embeddings and a probabilistic model (based on Gaussian processes) for validation and inference. The proposed model has several potential application areas, we demonstrate its use for multi-modal regression on a benchmark human pose estimation data set.
2007
Gaussian process latent variable models for human pose estimation
C. H. Ek, P. Torr, and N. D. Lawrence
International conference on Machine learning for multimodal interaction, 2007
Abstract
We describe a method for recovering 3D human body pose from silhouettes. Our model is based on learning a latent space using the Gaussian Process Latent Variable Model (GP-LVM) [1] encapsulating both pose and silhouette features Our method is generative, this allows us to model the ambiguities of a silhouette representation in a principled way. We learn a dynamical model over the latent space which allows us to disambiguate between ambiguous silhouettes by temporal consistency. The model has only two free parameters and has several advantages over both regression approaches and other generative methods. In addition to the application shown in this paper the suggested model is easily extended to multiple observation spaces without constraints on type.
Pre-prints
Abstract
The Kullback-Leilber divergence from model to data is a classic goodness of fit measure but can be intractable in many cases. In this paper, we estimate the ratio function between a data density and a model density with the help of Stein operator. The estimated density ratio allows us to compute the likelihood ratio function which is a surrogate to the actual Kullback-Leibler divergence from model to data. By minimizing this surrogate, we can perform model fitting and inference from either frequentist or Bayesian point of view. This paper discusses methods, theories and algorithms for performing such tasks. Our theoretical claims are verified by experiments and examples are given demonstrating the usefulness of our methods.
Abstract
We introduce Latent Gaussian Process Regression which is a latent variable extension allowing modelling of non-stationary processes using stationary GP priors. The approach is built on extending the input space of a regression problem with a latent variable that is used to modulate the covariance function over the input space. We show how our approach can be used to model non-stationary processes but also how multi-modal or non-functional processes can be described where the input signal cannot fully disambiguate the output. We exemplify the approach on a set of synthetic data and provide results on real data from geostatistics.